






Introduction
This study is the first attempt to apply a Bayesian state-space production (SSP) model to Korea chub mackerel (Scomber japonicus) population, which is a coastal-pelagic fish species distributed in a wide range of depths from the surface to continental slopes, down to around 300 m in warm and temperate waters (Castro Hernández & Ortega Santana, 2000). Given the data about annual yield from all fisheries, and annual catch-per-unit-effort (CPUE) collected from the large purse seine fishery, we chose a state-space surplus production model. Previous assessments for the population (e.g., Cho et al., 2009; Choi et al., 2004b; Choi et al., 2004a did not consider process errors in their analysis.
Surplus production models or biomass dynamics models have been studied because of their advantages over other assessment models. These advantages include simpler model structures and fewer model parameters to estimate (Carruthers et al., 2011; Chaloupka & Balazs, 2007; McAllister et al., 2001; Millar & Meyer, 2000b; Pedersen & Berg, 2017). Management reference points, such as the maximum sustainable yield (MSY) and the biomass that yields MSY are estimated (Prager, 1994; Punt, 2003). Despite these benefits, biomass dynamics models have been criticized for aggregating growth, recruitment, and natural mortality into a surplus production term, at the cost of biological realism (Millar & Meyer, 1999).
de Valpine (2012) proposed that a more realistic model provides a better estimation. Since a stock assessment model is a simplified version of a dynamic system, and fits fisheries data that are generally noisy, the variability should be considered for both the model and the data (Aeberhard et al., 2018). Adopting a state-space framework for production models can mitigate the simplicity of production models by incorporating process errors and observation errors. Process errors in a biomass dynamics model describe uncertainties of random effect parameters such as biomass, and observation errors account for the noise in the data. Despite the ability to account for these two sources of uncertainty, the inclusion of process errors requires the estimation of a number of free parameters, and high-dimensional integration. Over the past few decades, researchers have implemented state-space models under assumptions such as model linearity, which is ecologically unrealistic, within the frequentist statistical approaches. The development of statistical software such as ADMB-RE (Fournier et al., 2012; Skaug & Fournier, 2017) and TMB (Kristensen et al., 2016) has enabled the implementation of state-space models with Gaussian error structure using the Laplace approximation. Another advantage of ADMB-RE is that the program provides Markov Chain Monte Carlo (MCMC) sampling without any revision of the computer code. Because the numerical optimization of parameters could not be achieved without priors, we specified prior distributions to stabilize the numerical optimization.
Using the ADMB-RE software for implementing Bayesian SSP models, we estimated the annual biomass, intrinsic growth rate carrying capacity, and associated uncertainties. We further provided management reference points, including MSY, biomass that yields MSY (BMSY), and harvest rate that corresponds to MSY (HMSY). We also compared the performance of our model with those of others.
Methods
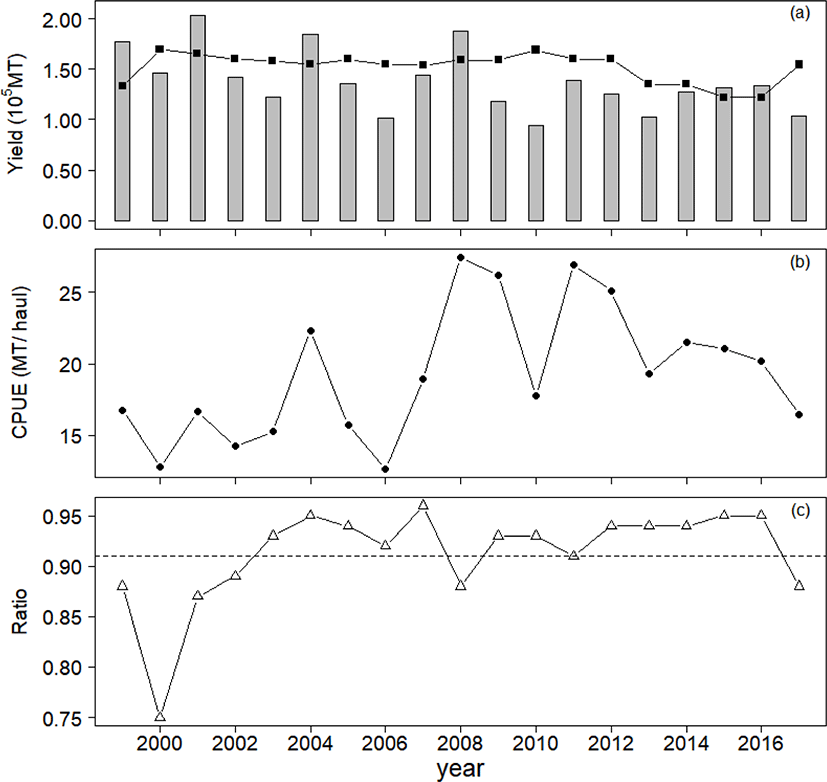
Two sets of historical data were used in this study: annual yield and catch-per-unit-effort (CPUE) for chub mackerel collected from Korean waters from 1999 to 2017 (Fig. 1). The Korean National Institute of Fisheries Science provided standardized CPUE with yield and effort data for 70% of the total large purse seine fisheries in Korea. We considered the chub mackerel CPUE (Fig. 1b) to be representative of all chub mackerel fisheries, as large purse seine fisheries accounted for more than 90% of the total on average (Fig. 1c).
We adopted a quadratic form of the Schaefer model formulated by Walters & Hilborn (1976) based on the original Schaefer model (Schaefer, 1954):
where Bt is the biomass in year t, Yt is the yield achieved by fishermen in year t, r is the intrinsic growth rate of the population, and k is the carrying capacity, or maximum population size. The second term on the right side of equation above contains the entire change in biomass, including growth, recruitment, and natural mortality in year t (Prager, 1994; Ricker, 1975), and this term is called ‘surplus production’ (Hilborn & Walters, 1992). Therefore, the Schaefer production model describes how the biomass at year t + 1 is related to the biomass in the previous year, with the model parameters r, k, and yield. Because the model assumes logistic growth or a symmetric curve of surplus production, the maximum surplus production occurs at k/2, which equals BMSY. MSY and HMSY can also be directly calculated based on rk/4 and r/2, respectively.
The model also depicts the measurement of the biomass using the following relationship:
where It is the CPUE collected in year t, and q is the catchability coefficient. The measurement shows that the CPUE obtained in year t is proportional to the biomass in the same year.
We then re-parameterized the model by dividing each term in the Schaefer model and the measurement equation above to downscale the biomass. The Pt terms in the following equations are the ratio of biomass to carrying capacity, or relative biomass (i.e., Pt = Bt / k). As Millar & Meyer (2000b) pointed out, using the relative biomass Pt rather than Bt in the model can reduce the extent of autocorrelation. Scaling Bt with k can improve the efficiency of numerical optimization, as described below.
We constructed a SSP model using the deterministic surplus production model described by Millar & Meyer (2000a). We assumed multiplicative errors that follow normal distributions, with means of 0 and variances of and for the biomass dynamics and observation, respectively.
Equation (1) is called the process equation, because it describes the dynamics of a system with process error. Equation (2) is called the observation equation, and specifies the relationship between the measurement and the state. Compared to the deterministic production model, the SSP model assumes that errors can arise from either of two distinct sources: model and data. The process error in equation (1) can be interpreted as the uncertainty of the model structure in describing system dynamics. Thus, Pt is treated as a random variable for process errors. The observation error in equation (2) accounts for errors in observation (i.e., CPUE), which can arise from measurement error or reporting error (Winker et al., 2018). Therefore, the parameters to be estimated in our model include relative biomass P=(P1999, P2000, …, P2018) and θ = (r, k, q, , ). To distinguish the different types of parameters in our model, we denote the P as random-effect parameters or states, and the time invariant constant parameters, θ, as fixed effect parameters.
We built likelihood functions for the process equation and observation equation described above. The Pt+1 follows a log-normal distribution, with log Pt+1 having the mean of log{Pt + rPt(1 − Pt)−Yt/k} and variance of , written as follows:
Likewise, log It follows a normal distribution with the mean of log{qkPt}and variance of :
Therefore, the likelihoods built using the process and observation equations have the following form, with assumptions of independence:
With likelihood functions (3) and (4), the joint likelihood function is as follows.
Note that D = (I, Y), where Y = (Y1999, Y2000, …, Y2017), and I = (I1999, I2000, …, I2017).
Haddon (2011) argued that data availability governs the complexity of stock assessment models. While the SSP model takes into account the variability in biomass dynamics, which improves realism, it has a large number of free parameters that must be estimated with the given data. Prager (1994) suggested that additional information is required for parameter estimation in state-space models.
As mentioned earlier, the script software ADMB-RE implements SSP models using the Laplace approximation, to estimate fixed and random effects separately (Skaug & Fournier, 2017). That is, random effects are separated from the joint likelihood function (i.e., ꭍ logL(θ, P|D)dP = logL (θ | D) in numerical optimization. Because numerical optimization was not achieved, we introduced prior distributions for parameters, r, k, q, , , and the relative biomass in the first year, P1999. Although informative priors should be considered carefully, the population parameters of chub mackerel in Korean waters have not previously been studied. Therefore, we tested various prior sets and selected the one best suited for numerical optimization. In practice, we chose log-normal distributions for r and k, whose distribution domains are positive. We chose inverse gamma distributions for the variances of errors, and , to assign prior distributions with positive support. These prior distributions have been used in previous studies focusing on Bayesian stock assessments (Chaloupka & Balazs, 2007; Meyer & Millar, 1999; Millar & Meyer, 2000b; Winker et al., 2018). Because the catchability coefficient is a scaling factor, we assigned a uniform prior for logq (McAllister et al., 1994; Millar & Meyer, 2000b). We considered a log-normal prior for relative biomass in 1999, P1999. To address uncertainties on priors, we chose priors with the coefficient of variations (CVs) larger than 50%. The selected parameter set is shown in Table 1.
Taking a Bayesian approach, the probability that a parameter is updated is based on the prior distribution and likelihood. Assuming mutual independence of the priors, the joint prior has the following form:
With the joint likelihood and the joint prior, the posterior is defined by Bayes’ rule:
Because high-dimensional integration is required to calculate the full posterior distributions, which cannot be achieved in closed form, we generated MCMC sample sets using the ADMB-RE software. We thinned out every 50,000th MCMC sample sets over 0.2 billion iterations to reduce the autocorrelation for each parameter. The first 100 sample sets (i.e., the initial 5,000,000 sample sets) were then removed as a burn-in period. We assessed four criteria to check the convergence of the MCMC samples for parameters r, k, q, , , and P1999: (i) the dependence factor of the Raftery-Lewis statistics, (ii) the lag-1 correlation, (iii) the ratio between the naïve standard error and the time series standard error, which is corrected for autocorrelation, and (iv) the unimodal histogram of MCMC samples for each parameter. The first three were carried out with R package, “coda (Plummer et al., 2006), where we used default values (e.g., error margin (= 0.005) and probability of obtaining an estimate in the interval (= 0.95) for Raftery-Lewis statistics). We determined the convergence of the samples when the dependence factor of the Raftery-Lewis statistics was less than 5, the lag-1 correlation was close to 0, and the ratio of the naïve standard error to the time series standard error was around 1, indicating that no autocorrelation was present. The summaries of the posterior distributions give modes as point estimates and uncertainties as 95% credible intervals.
To compare our results, we applied various other production models to the same data. The selected models included the Fox production model (Fox, 1970), Yoshimoto-Clarke model (Clarke et al., 1992; Yoshimoto & Clarke, 1993), the Schnute regression model (Schnute, 1977), the ASPIC program (Prager, 2016, 1994), and the Observation model. The Fox model, commonly referred to as the exponential (production) model, assumes an exponential relationship between fishing effort and population size (Fox, 1970):
where I∞ is catch per unit effort, which is proportional to the carrying capacity, k, and Et is the effort in year t. Since the model regards surplus production as yield, it assumes that the stock is at equilibrium. Hilborn & Walters (1992) criticized the model on the grounds that equilibrium conditions rarely occur, and stock size is usually overestimated. Clarke et al. (1992) and Yoshimoto & Clarke (1993) modified the Fox model, implementing non-equilibrium conditions, as a linear regression model. Using this model, Yoshimoto & Clarke (1993) showed that their model predicted CPUE data well, even with negative estimates of q and k. We denote this model the Yoshimoto-Clarke (YC) model:
Schnute (1977) transformed the Schaefer model into a linear regression model which allowed the use of explanatory variables with geometric means of CPUE and effort data.
We chose these three models to compare, as they have been used frequently in recent publications and technical reports in Korea (Cho et al., 2009; Jeong and Nam, 2017; Kim et al., 2018; Kwon et al., 2013).
The ASPIC program was developed by Prager (1994), and has been included in the NOAA toolbox (https://nmfs-fish-tools.github.io/). Among the various modes available for fitting the data, we fitted the Schaefer model through the least squares method, to provide results without process and observation errors. The other former models estimate r, k, and q as free parameters, and the ASPIC program estimates four free parameters: r, k, q, and B1999.
Ft in the model is fishing mortality rate. The unit for the estimates of r and q are year−1 and year−1 haul−1, respectively.
When the process error is removed from equation (1), the Observation model depicts deterministic biomass dynamics and variability in measurement. Without process errors, the relative biomasses from 2000 onward (i.e., P2000, P2001, …, P2018) are calculated as derived parameters, which do not require the Laplacian approximation. Therefore, the estimation of the model parameters was performed within ADMB through maximum likelihood estimation, instead of using ADMB-RE. Because the Observation model considers the observation error, the model estimates one more parameter, , than the ASPIC program.
Results
With the specified priors and data about yield and CPUE, we obtained posterior distributions for each parameter (r, k, q, , , P1999) using MCMC samples. We determined our MCMC samples built converged posterior distributions for each parameter (r, k, q, , , P1999), while accounting for the diagnostic results provided in Table 2. For each sample set of parameters, the dependence factor of the Raftery-Lewis statistics was around 1, the lag-1 correlation was around 0, the ratio between naïve and time series standard errors was around 1, and the posterior distribution was unimodal (Table 2 and Fig. 2).
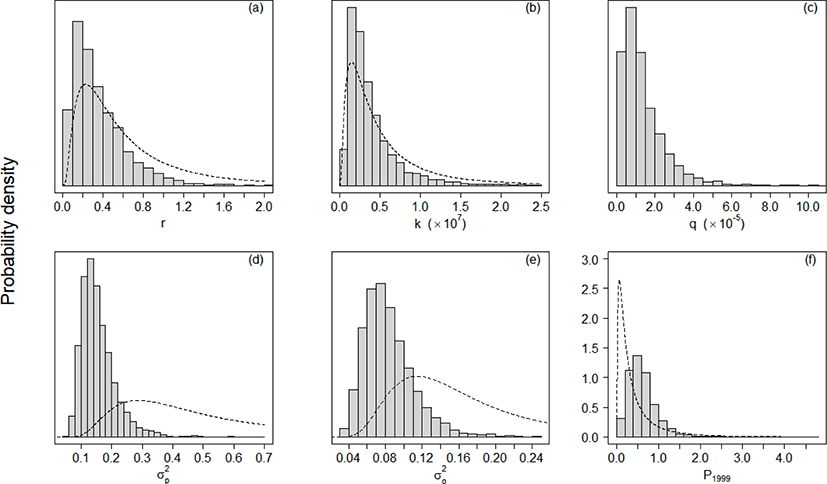
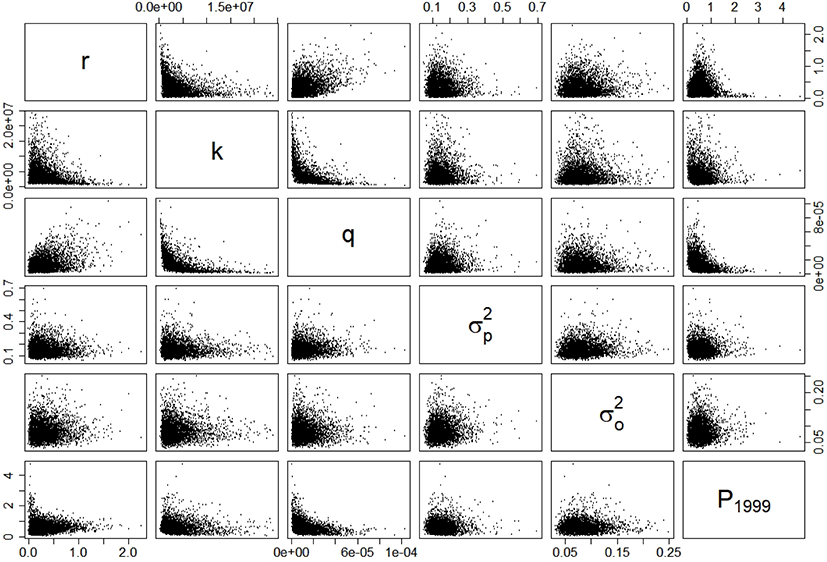
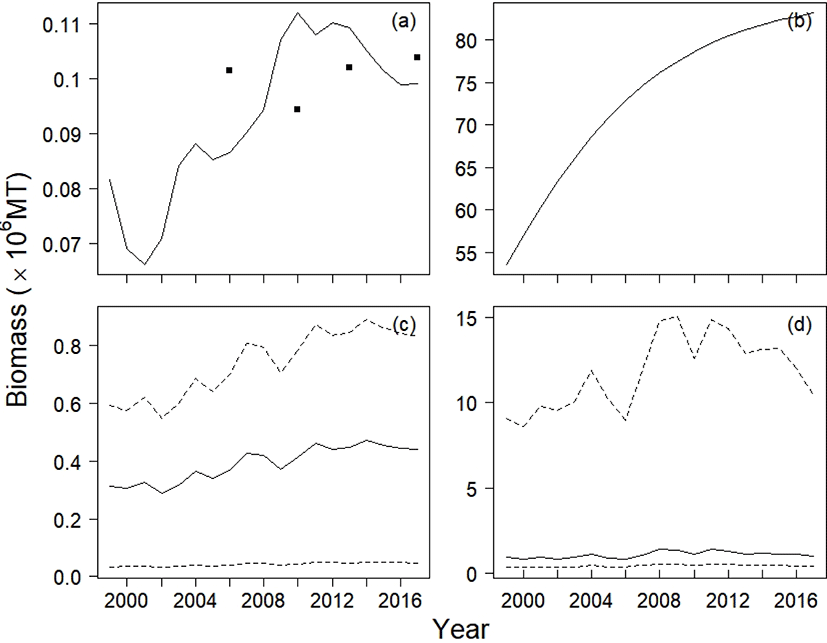
The estimates (posterior modes) of intrinsic growth rate r, carrying capacity k, and catchability q were 0.16, 1,832,623 metric tons (MT), and 5.49 × 10−5 haul−1, respectively. The CV of the process error was nine times larger than that of the observation error, calculated as 84% and 9%, respectively. Based on the estimates of r and k, the calculated management reference points MSY, BMSY, and HMSY were 152,677 MT, 910,866 MT, and 0.08, respectively. Table 3 lists the 95% credible intervals for each parameter. Based on the scatter plots of joint posterior samples for both parameters, r and q exhibited negative relationships with k (Fig. 3). The former relationship can arise when the stock is large with low productivity, or small with high productivity (Millar & Meyer, 2000b; Walters & Martell, 2004). Millar & Meyer (2000b) also mentioned that the carrying capacity k in equation (2) scales the biomass Bt down and is highly correlated with q.
Our model result followed the CPUE data with increasing or decreasing trends (Fig. 4a). The annual yields achieved in 1999, 2001, 2004, and 2008 were larger than MSY, whereas those in other years were below MSY(Fig. 4b). The average yield of chub mackerel during 1999–2017 was 90% of MSY, but it was 78% (119,393 MT) during 2009–2017.
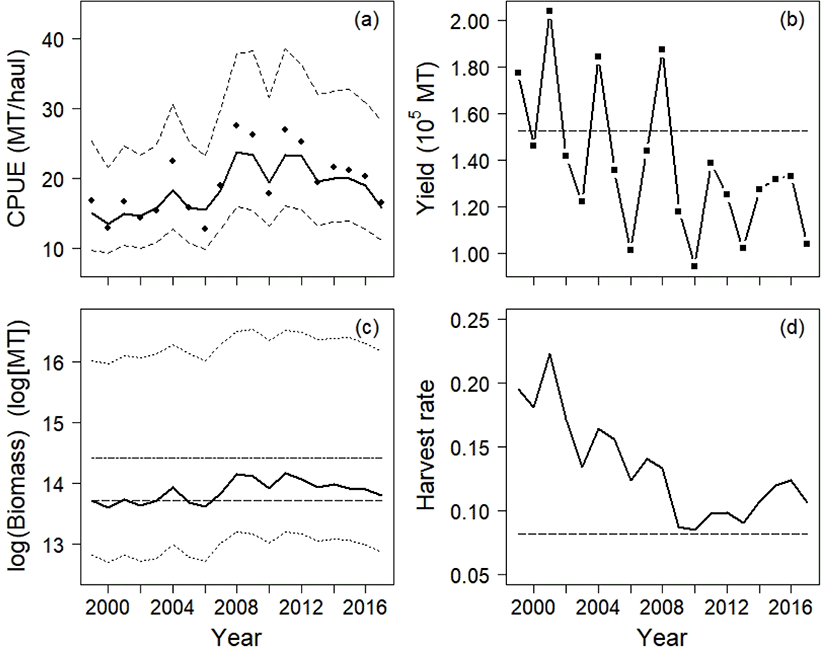
The annual biomass was below the carrying capacity, and the biomass was smaller than BMSY in 1999, 2000, 2002, 2003, 2005, and 2006 (Fig. 4c). From 2007 onward, the predicted stock size was greater than BMSY. The mean biomass from 1999 to 2017 was 1,064,924 MT, and the smallest and largest biomass values were 805,645 MT and 1,419,278 MT, respectively. The harvest rate, the proportion of yield to biomass, decreased during this period (Fig. 4d). The annual harvest rate remained above the calculated HMSY.
Applying the various production models, we obtained parameter estimates for each model (Table 4). The Fox and Schnute regression models gave negative estimates for carrying capacity and catchability coefficient, which are biologically absurd values. The population growth rate estimated with the Fox, YC, and Observation models war larger by about 10 to 17 times than that with the SSP model. The Schnute model interpreted the stock size as decreasing (−0.35), whereas the ASPIC program showed that the stock grew by 0.18 per year. The YC model estimated the smallest carrying capacity among the production models (160,198 MT), whereas the ASPIC program estimated the largest value (85,693,999 MT). The Observation model estimated the carrying capacity as 596,002 MT, which is about 33% of that of the SSP model. The YC model estimated the largest value for catchability coefficient (2.05 × 10−5 haul−1year−1), and the ASPIC program estimated the smallest value (2.59 × 10−7 haul−1year−1) among the production models. The Observation model estimated a catchability coefficient roughly 10 times larger than that estimated by the SSP model (4.88 × 10−5 haul−1). The Observation model estimated the variance of the observation error as 0.03, roughly 42% of the corresponding SSP model estimate. All production models estimated the relative biomass in the first year, P1999, within the range 0.48 to 0.60. We excluded the Fox and Schnute models in comparisons of predicted CPUE and biomass trajectories because of their unreliable estimates, as evidenced by their negative values for k and q.
The 95% confidence intervals for parameter estimates for the Observation model and 95% credible intervals for the SSP model are provided in parentheses.
The predicted CPUE and biomass from the four models are listed in Figs. 5 and 6. Although all four models moderately explained the CPUE data, the residual sum of squares (RSS, equation (8) showed that the SSP outperformed the other three models in predictive accuracy (RSSYC: 227.44, RSSASPIC: 280.78, RSSObservation: 248.29, RSSSSP: 79.91):
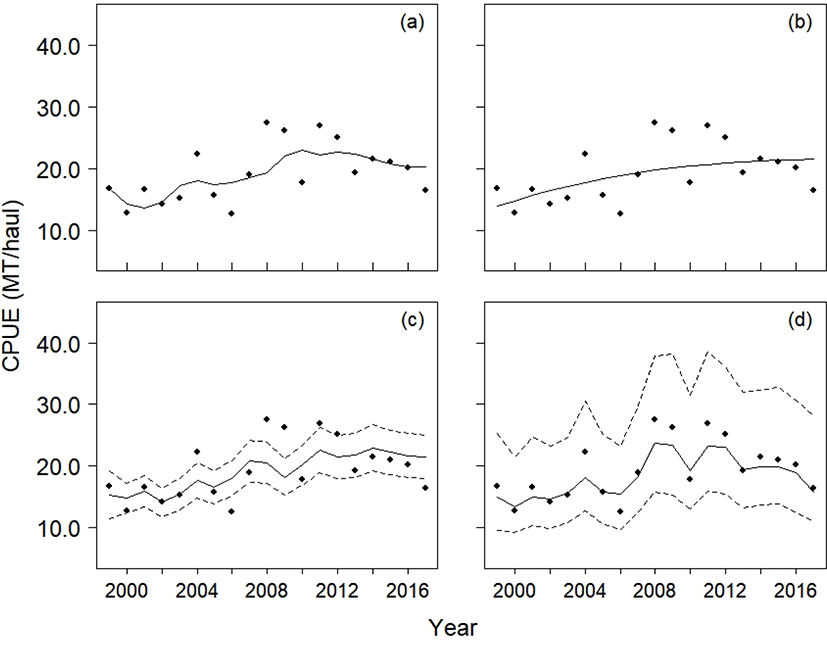
The 95% confidence intervals for the Observation model did not include the CPUE data, whereas the 95% credible intervals calculated from the SSP model did (Fig. 5c, 5d).
Although the YC model had second smallest value of RSS, it only explained the yield in years 2010 and 2013 (Fig. 6a). In the ASPIC program, the stock biomass showed monotonic increases from 1999 to 2017 (Fig. 6b), and its stock size was the largest among the four production models. The ASPIC program estimated that the average yield from 1999 to 2017 was 137,779 MT, suggesting that the stock was underexploited. The Observation model and the SSP model predicted the annual biomass to be larger than the annual yield.
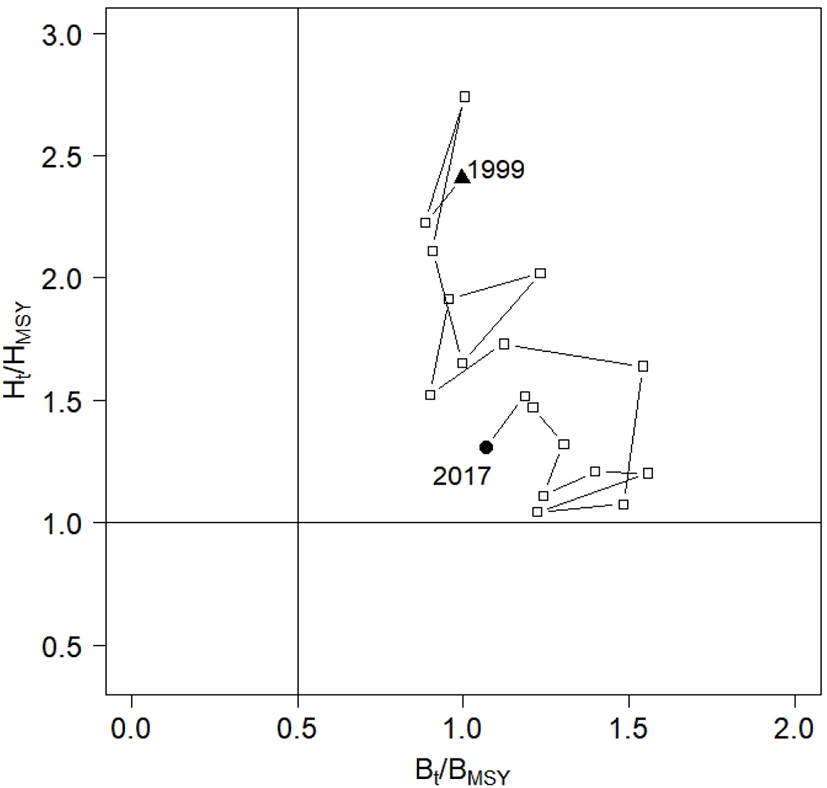
According to the National Oceanic and Atmospheric Administration (NOAA), the terms ‘overfishing’ and ‘overfished’ apply when stocks have a harvest rate larger than HMSY (Ht > HMSY) and the stock size is smaller than 0.5BMSY (e.g., 0.5BMSY > Bt). Using these definitions, we depicted the historical trajectories of the annual harvest rate and biomass in a Kobe plot (Fig. 7). The plot suggests that the stock was subject to overfishing from 1999 to 2017, and that the harvest rate exceeded HMSY. After 1999, the annual harvest rate showed a decrease. However, the annual biomass was larger than 0.5BMSY, indicating that the stock was not overfished during the 1999–2017 period. The graph shows a small increase in the ratio of annual biomass to BMSY, from 1.00 in 1999 to 1.07 in 2017.
Discussion
The goal of fisheries management is to maximize the profit from the catch, while also effectively conserving fish stocks (Quinn & Deriso, 1999). Estimates of growth rate and carrying capacity are directly used to calculate management policies, so estimating model parameters is crucial not only to understanding the biological properties of a population, but also to determining optimal management practices for the species.
Chub mackerel have been fished by large purse seine fisheries under quota management since 1999. In 2017, the total allowable catch (TAC) was set at 123,000 MT (Korean Ministry of Ocean and Fisheries, 2017), which was 80.56% of the MSY calculated in the present study. Hilborn (2010) introduced the concept of a ‘pretty good yield’ for managers, defined as 80% of the MSY. However, since the method of calculating TAC is not available to the public in Korea, these two values cannot be directly compared. Because the minimum legal size for chub mackerel is a total length of 21 cm, the predicted annual biomass in the present study must be interpreted as the biomass of fish larger than 21 cm. The quota in 2017 can therefore be said to be optimal only if the TAC targets the stock biomass within the legal size.
Although this study provides management principles for Korean chub mackerel, it can be dangerous to base management strategies for a species on estimates produced by a single model. We therefore strongly suggest evaluating various alternative models before setting management goals based on our results.
Compared with age-structured models, surplus production models have fewer requirements for historical data, fewer model parameters to be estimated, and simpler model structure. Setting aside these advantages, the main weakness of the present study is related to the model structure. First, because the surplus production term in the model is combined with recruitment, natural mortality, and growth, our model cannot generate separate estimates of annual recruitment and natural mortality. Therefore, age data for the stock should be collected and applied within an age-structured model, such as a statistical catch-ag-age model, not only to assess the stock year-class strength, but also for cross-validation of the estimates. Second, while chub mackerel is a highly migratory species, distributed from the East China Sea to Kurile Island (Castro Hernández and Ortega Santana, 2000; Lee & Kim, 2011; Wang et al., 2014), the model does not consider immigration or emigration. In addition to its wide range of habitats, chub mackerel is exploited by Korea, China, and Japan, in adjacent fishing grounds, which are located in the East China Sea and adjoining waters. This weakness could be addressed by aggregating annual yield and CPUE data from all three countries and applying the SSP model to assess the stock as a single population. Hiyama et al. (2002) used two data sets, one collected from Korea and one from Japan, and estimated the stock size as a single population in the East China Sea and Japan Sea based on chub mackerel migration patterns. This simple approach may provide better estimates of model parameters once rigorous studies have been conducted on the migratory pattern of the species.
State-space models, comprising process and observation equations, explicitly quantify uncertainties arising from model structure and measurement; process errors and observation errors. As mentioned above, the inclusion of process errors in our model increases the number of free parameters, such as annual biomass, and therefore necessitates additional information for parameter estimation (Prager, 1994). Carruthers et al. (2011) recommended the inclusion of prior distributions on r and k for production models, because fisheries data often contain insufficient information to obtain reliable estimates. Hilborn & Walters (1992) coined the term ‘data failure’ for instances in which the fisheries data include insufficient information about model parameters, leading to unreliable parameter estimates. For example, the negative values for carrying capacity and catchability coefficient in the Fox and Schnute model resulted from insufficient information in the data. In addition to ‘data failure’, the posteriors obtained from SSP also support this point. The posterior distributions of r and k reflected the shape of prior distributions (Fig. 2a, 2b). Posterior distributions of parameters are updated based on priors and likelihood, and the yield and CPUE data on chub mackerel did not provide sufficient information about r and k; as a result, the posteriors mirrored the corresponding priors. In practice, however, collecting data which provide sufficient information for parameter estimation is rarely possible. Therefore, the term ‘data failure’ can be translated to ‘model failure’, as models do not accurately depict biomass dynamics (Carruthers et al., 2011; Millar & Meyer, 1999; Musick & Bonfil, 2005; National Research Council, 1998; Pedersen & Berg, 2017).
While the four production models (YC, ASPIC, Observation, and SSP) fitted the CPUE data moderately well, the results showed that the SSP production model should be preferred over the others for explaining CPUE data with fluctuations. In particular, the RSSs showed that the SSP model performed best in explaining the CPUE data. While the RSS suggested that the YC model explained the CPUE data second best among the four models, the YC model failed to account for the yield in 2010 and 2013. The ASPIC program indicated that the stock was severely underexploited throughout the whole duration of the study. To be specific, the mean ratio of the Bt to BMSY was 1.6, and the mean ratio of Ft to FMSY (fishing mortality rate that corresponds to MSY) was 0.02. The ASPIC program may therefore provide an optimistic view of chub mackerel stock, which allows fishermen to exploit the stock more extensively than does the present level. The Observation model provided uncertainties for the predicted CPUE, as did the SSP model. However, the intervals of the model were too narrow to include the CPUE data (Fig. 5c), which, could be addressed by the SSP model (Fig. 5d). The Observation model therefore may consider the observation errors only, whereas the SSP model incorporated both process and observation errors, resulting in wider credible intervals for the predicted CPUE. In short, a SSP model can be a solution for CPUE data with fluctuations.
Priors were a key factor in the implementation of the SSP model. In practice, we used the mode and CV to determine hyperparameters for each model parameter, and then obtained prior distributions through trial and error, to stabilize the numerical optimization. As the priors contain information on parameters, biologically absurd priors were excluded. For example, positive values were chosen for the modes of growth rate r, catchability coefficient q, and P1999. The mode for carrying capacity, k, was only selected when its value was larger than the largest yield. To address our uncertainty regarding priors, we set the CV to be larger than 50% for each parameter. The posterior distributions obtained with the priors and likelihood function in the present study can be used as priors in future studies on Korean chub mackerel. The script software ADMB-RE performed both numerical optimization and MCMC sampling. Although we selected priors that assisted in the numerical optimization of the likelihood function, it is also possible to obtain posterior distributions through the script software without editing its code. Therefore, we recommend taking advantage of this powerful statistical tool for the implementation of Bayesian state-space models.
Conclusions
This study aimed to fit CPUE data with fluctuations, and to assess Korean chub mackerel stock. We applied a SSP model to the annual yield and CPUE data collected from 1999 to 2017, with prior distributions for the model parameters (r, k, q, , , P1999), using the software ADMB-RE. We estimated model parameters including intrinsic growth rate r, carrying capacity k, and annual biomass, and provided management references (MSY, BMSY, and HMSY). We concluded that Korean chub mackerel stock have been subjected to overfishing, but were not overfished during 1999–2017, based on the trajectories of Ht / HMSY, and Bt / BMSY. The findings of this study suggest that practitioners should choose a SSP model which considers two sources of variability, and to fit the CPUE data with fluctuations. Further studies into the migration patterns of chub mackerel must be carried out in order to assess the stock as a single population fished in the East China Sea.